Reveal to Present Optical Character Recognition Evaluation at JSM 2025
In August, Data Science Fellow Maddie Kelsch will present research findings at the Joint Statistical Meeting (JSM) 2025, the largest gathering of statisticians in North America. The paper gives insight into how to evaluate Optical Character Recognition (OCR) models and what characteristics of a document affect performance. The research, conducted in partnership with her team from University of Michigan School of Information, looks specifically at the National Archives and Records Administration’s (NARA) OCR model comparing human transcriptions and model transcriptions through both quantitative and qualitative methods. JSM offers a unique opportunity for statisticians in academia, industry, and government to exchange ideas and explore opportunities for collaboration. Learn more about it here.
A Framework for Evaluating Optical Character Recognition (OCR) at the National Archives and How We Might Improve Accuracy
By Maddie Kelsch, Data Science Fellow
Prepared for Joint Statistical Meeting in August 2025
Introduction
The National Archives and Records Administration (NARA) contains billions of documents of historical significance that await digitization for public access, researchers, and more. For decades, NARA has relied on volunteers to transcribe collections, but this approach is time-consuming and labor-intensive. Transcriptions are used to populate search results so users can refer to document collections and record groups as historical sources in a multitude of settings. Advances in optical character recognition (OCR) offer a more scalable approach, and NARA’s deployment of OCR in 2024 promises a quicker delivery of these documents to the public. However, OCR models remain a new technology with known limitations on handwritten language, for example, and there is little written on the performance of OCR models on historical documents or how OCR practitioners might address these performance limitations. The evaluation framework and results from our research below will be presented at the Joint Statistical Meetings (JSM) in Nashville on August 4, 2025.
Establishing an Evaluation Framework for Diverse Document Collections
We created scores using two evaluation metrics for quantitative comparison: Recall-Oriented Understudy for Gisting Evaluation (ROUGE) and Character Error Rate (CER). Both sets of metrics calculate accuracy by comparing generated text to a reference text (i.e. human annotation). Both metrics are lexical measures, meaning the character sequence correctness is assessed. These measures were preferred to semantical measures, which focus more on the similarity in meaning. ROUGE and CER together offer a balance between correct sequential words and strict character comparison, approaching how a human-user would distinguish a good translation from a bad one.
The sample included 759 documents from 160 different collections. We calculated scores for each document and used a two-sample t-test to compare average performance based on two factors we believed might affect the model’s accuracy: the age of the document (its year of origin) and the type of text it contained (typed, handwritten, or a mix of both).

ROUGE-L Scores by Document Type
Source: Madeline Kelsch, Madison Hall, Conor York, Tianyu Hu, Cameron Milne, and Taylor Wilson. Optical Character Recognition Evaluation for Historical Archival Records. Presented at the Joint Statistical Meetings, 2025.
In the ROUGE score compared to type of document analysis, we found that there was a statistically significant difference between all types of documents.
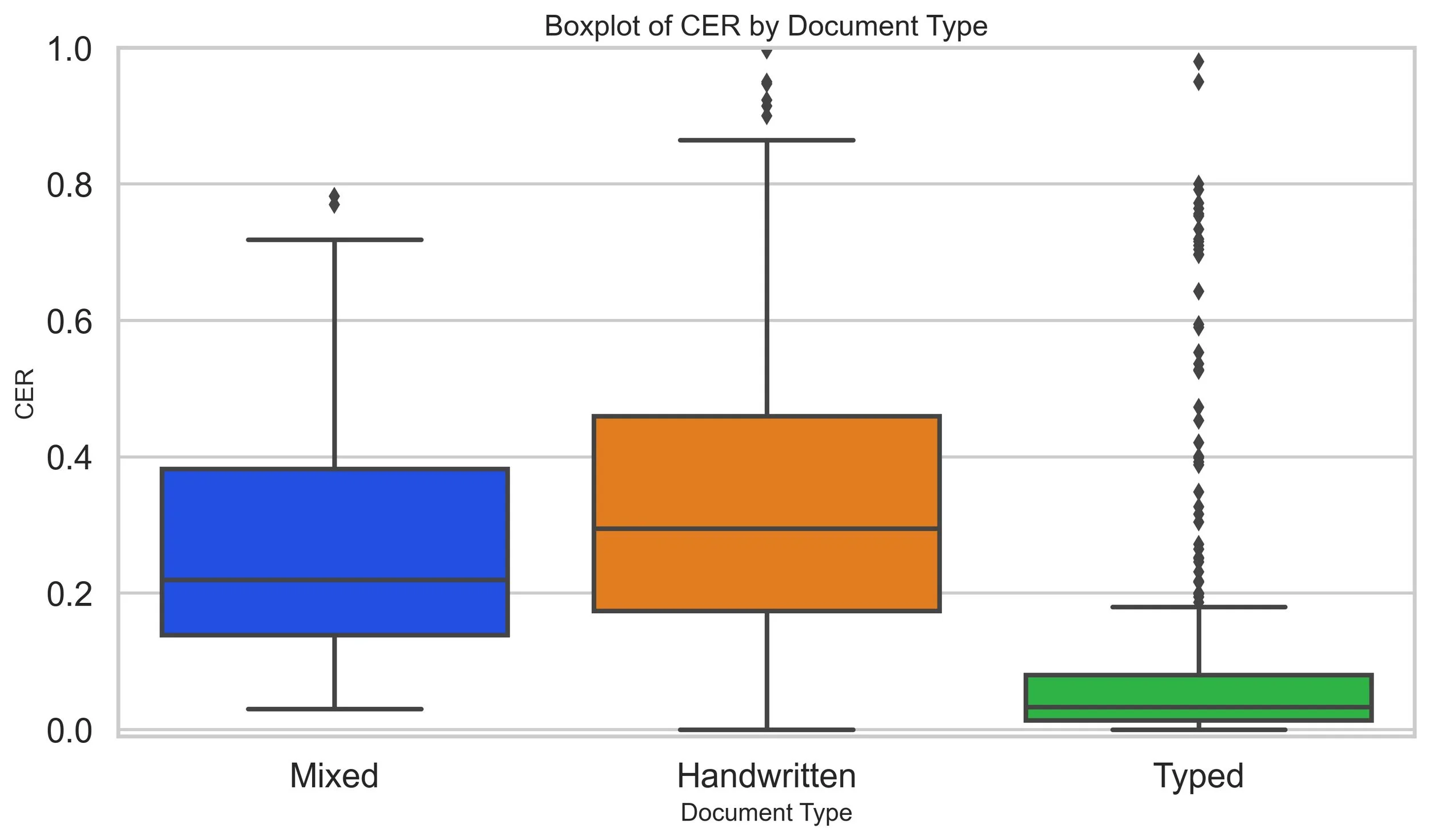
Boxplot of CER by Document Type. Madeline Kelsch, Madison Hall, Conor York, Tianyu Hu, Cameron Milne, and Taylor Wilson. Optical Character Recognition Evaluation for Historical Archival Records. Presented at the Joint Statistical Meetings, 2025.
Likewise, in CER score analysis, we found a statistically significant difference in means between all document types.
In addition to our analysis that isolated the type of a document, we also used ordinary least squares linear regression to address age as a variable in both CER and ROUGE scores. In this analysis we found there to be no evidence that suggests age is predictor of score.
The scores previously calculated were then leaned on in an ensemble approach to classify documents as “best” and “worst”. Ensemble scores were created with the formula: Ensemble Score = -[(1 - ROUGE) + CER]. The ensemble score afforded us an easy ranking system and a response to documents with high ROUGE scores, but low CER scores.
Results and Observations
The best performers in ensemble scoring were exclusively typed documents, reinforcing our statistical tests. Among these documents, we observed the following:
Lengthier documents did not result in worse transcriptions.
Formatting differences such as differing indentations, rotated text, and two-column presentations, also did not challenge transcription accuracy assuming the text was intended to be read from left to right.
Legibility was clear in each of the best performers, suggesting a pattern important for performance.
Among the worst performers, several more patterns emerge:
Handwritten documents were consistently less accurate than typed.
Many of the documents consisted of ink stains from the other side of the document, distorting CER rates in particular.
Some documents had high ROUGE and disproportionately high CER scores often due to incorrect word order. This was common in texts with non-linear layouts (e.g., newspapers with columns), where the OCR model failed to follow the intended reading sequence.
On the other hand, there were traits that continuously stumped human transcribers and the OCR model. For example, faded text, cursive handwriting, aggressive aging, water damage, impression lines, and unique handwriting styles caused poor OCR transcription and human error (e.g. “[illegible]” in transcription) when it overlapped the text. While older documents more consistently contained one or more of the traits that directly impacted text legibility, it was still a prevalent issue among all years.
Atypical OCR Behavior
Within our analysis of the thirty worst performing documents, we found a trend in the OCR to provide upside down translations. In some heterogeneous formats, the OCR model couldn’t distinguish the rotation of the text and tried to transcribe it upside down (see example below). This odd behavior is essential to eliminate to improve OCR transcriptions.

Snippets from the National Archives documents and transcriptions.
Suggestions to Strengthen OCR Output Using Collaborative Human Artificial Intelligence (AI) Workflow
Our findings indicate the use of OCR by NARA on typed documents suffers little from inaccuracies, and scalable deployment will offer immediate value. For handwritten documents, trends of irregular segmentation, different text alignments, and ink bleeding, we propose a strategy for balancing OCR transcription with human review: we suggest human efforts start with a choice of ‘boxing’ around text that is then transcribed by OCR. If a transcriber gets to a document and believes the model would be able to produce an accurate transcription faster via boxing, they can choose to box the document instead. By boxing, the OCR model errors caused by its own programmatic faults will significantly decrease. For example, text that bled through won’t be in the area the model transcribes, text with multiple rotations will not be perceived as a whole, etc. This human-in-the-loop architecture will still rely on volunteer efforts but in a much more resource efficient way.

Original document: Great Lakes Bulletin
A document could possess multiple boxes and the text within each box would then be ordered corresponding to box order, as shown above. Additionally, the rotation of the text would be determined by the corner where the volunteer starts the box, the starting corner would be considered the top side of the text. Both intuitive features built into the boxing methodology would ensure that OCR errors would significantly decrease, simply by erasing confusion. By using OCR technology in combination with human volunteers, more documents can be accurately transcribed and increase public access to information. Our proposed solution allows a feasible way to combine machine power with human power to do just that.
Moving Forward
By using OCR technology in combination with human volunteers, more documents can be accurately transcribed and increase public access to information. Reveal’s proposed solution allows a feasible way to combine machine power with human power to do just that. Contact the Reveal team to learn more about how we can improve the accuracy of optical character recognition, together.